© Estwald ISI 2015 - 2026


Estwald’s
Information System Infrastructures











Databases
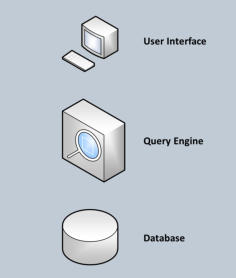
A database programs, such as Microsoft Access, Oracle, SQL Server, and MySQL, consist of three components; the user
interface, a query engine, and a database file. They differ in the location of the components
and the size of the database.
Most database programs can be run on a workstation. In this case all three components
are held on the workstation’s storage device and generally accessible only to the user of that
workstation. Microsoft Access and SQL Server Express are well suited for this situation.
But if multiple personnel need access to the database then the database file must be
placed in a shared location be it a server directory or a shared directory on a workstation. The
user interface must be available to all users at their workstations either through a local
program or a website via browser. With the user interface and database separated on the
network the placement of the query engine becomes paramount.
How a Database Works
The database file, commonly referred to as the back end, contains one or more schema. A schema is container that holds
a group of related tables containing records and depending on the database program may also contain related triggers,
procedures, views, queries, indexes, and reports. The schema’s metadata file contains all information related to the structures
and objects contained in the schema.
An individual at the user interface, commonly called the front end, creates a query. He or she may not know that’s what
they are doing when they fill in a group of fields in a form but once the fields are filled and the OK or Continue button is pressed
a structured query language (SQL) statement is created. Query statements are generally only a few hundred bytes in length
and take the form:
SELECT field FROM table WHERE field = “value” ORDER BY field ASCENDING;
This is a simple query requesting a single column from a single table if a given condition is met with the resulting recordset
being returned to the user interface in alphabetical order. Queries can become quite complex when multiple tables and fields
are involved so do not be fooled into thinking this is an easy task.
Once created, the query is sent to the query engine for processing. The query engine parses the command, opens the
database file, opens the appropriate schema, performs the actions required to fulfill the request, closes the schema and file,
and sends the results of the operation back to the user interface.
Given the database file can be several megabytes to several thousand gigabytes in size and that a query may require the
engine to access the file multiple times in order to complete a complex query it is essential that the data path between the
engine and the database file be as fast as possible whereas the path between the engine and user interface need not be since
the traffic between them consists only of the sent query and the return of a resulting recordset.
Types of Database Programs
Microsoft Access and similar database programs incorporate the query engine in the workstation executable program
along with the user interface. The database file may be incorporated with the user interface portion of the program or it may be
separated and placed elsewhere but in no instance can the query engine be separated from the user interface and moved
closer to the database file. So when a query is executed the engine must bring the entire database file to the workstation over
the network, sometimes several times, to complete a task. And if multiple users are attempting to access the file they must wait
in turn for it to become available as two tasks can not be performed on the file simultaneously. Network congestion can become
severe slowing down all network activity.
MySQL and Oracle type databases house the engine and file on a single platform, a database server. the user interface
can be virtually anywhere and in multiple forms, websites for some users and a program for others depending on their
respective needs. This keeps the majority of traffic between the server CPU and the local storage device which is a far faster
data path. further the query engine accepts all incoming jobs and places them in a local queue. These query engines are multi-
tasking and can send multiple threads to multiple cores so several jobs can be processed simultaneously.